淘秀网架构与使用技术总览
淘秀网架构与使用技术总览
基于Elasticsearch/SpringBoot/Redis/RabbitMQ/Mybatis/Dubbo/Vue/MySql,结合Scrapy爬虫数据挖掘的网站建设。
最近在工作之余的时间,学习了一些新的技术,于是想做一个项目,用来巩固这些新技术。淘秀网就在这样的一个背景下诞生了,网站集成数据挖掘, 数据处理与展现于一身,其本身更像个搜索引擎。所有信息都是通过爬虫获取得到。
用户可以在网站上输入感兴趣的关键词,当用户输入一个关键词,网站展现出淘宝网中关键词相关产品的买家秀,用户可以通过查看买家秀的方式来决定是否购买当前产品,点击相应链接,前往淘宝网相关产品页面完成购买。
构架
- 数据端
- Scrapy爬虫框架(Python)
- 数据库
- Mysql
- 搜索服务器
- 后端服务
- Spring Boot
- Dubbo
- Redis
- RabbitMQ 消息队列
- Mybatis-Plus
- Druid
- ZooKeeper 注册中心
- Maven
- Swagger2:Api文档生成
- 前端服务
- Vue
- element-ui
架构图
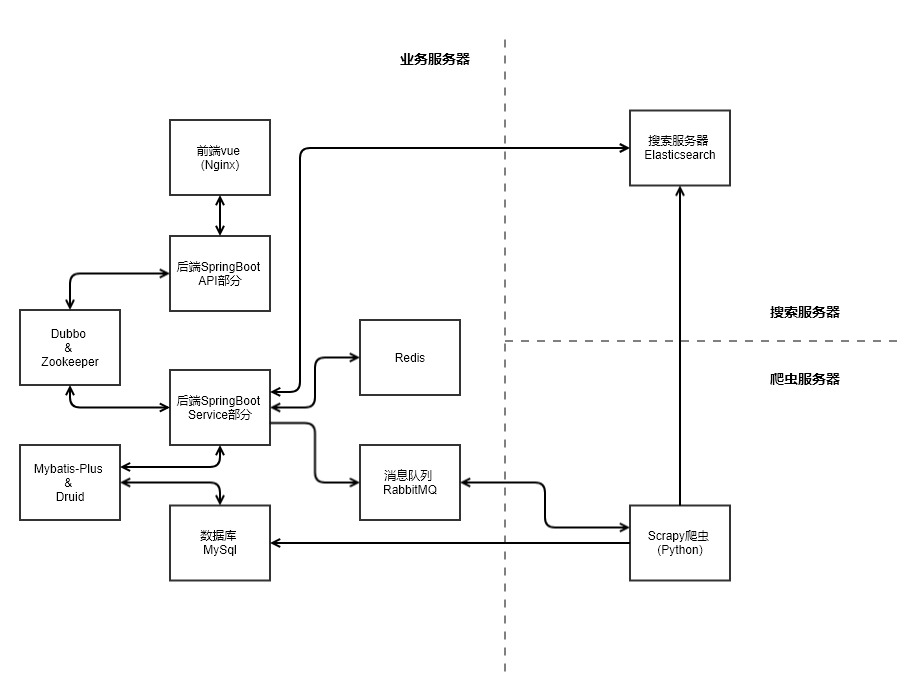
网站分为四个部分,三台服务器。其分别为后端数据获取部分,也就是上面的爬虫服务器 后端业务逻辑部分与前端展现部分, 也就是上面的业务服务器,搜索部分,也就是上面的搜索服务器。
- 后端数据获取部分
后端数据获取部分主要由Python爬虫来完成,爬虫会根据相关关键字去获取目标网站相应的信息,取回信息后将信息存入数据库,同时也将数据存入搜索服务器以便后面后端业务的调用。 - 后端业务逻辑部分
这部分主要由SpringBoot以及相关技术组成,用来处理网站的业务逻辑,查询逻辑,关键词分析等。当用户输入一个关键词或者短语时,系统会从搜索服务器获取相关信息,返回给前端展现, 同时系统会对用户输入进行分词分析,提取更有效的关键词,当这个关键词不存在于我们系统中时候,系统将会通过队列异步调用数据获取部分(也就是爬虫部分)重新获取数据, 后端业务逻辑部分相当于整个网站的调度中心,拥有分析处理调度挖掘等功能。
同时也使用了Dubbo和zookeeper注册中心将api部分与业务实现部分分离,提高了后端的可扩展性与可维护性。使用Redis做缓存处理。 - 前端展现部分
这部分由现在比较流行的前端MVVM框架Vue来完成一个简单的搜索展现页面,配合element-ui可以达到一个较好的表现效果。 - 搜索服务器部分
使用了Elasticsearch作为我们的搜索服务器,目前看起来他的表现还是相当不错的。
关于关键词的处理
当用户输入一个关键词或者短语时,无论这个关键词之前是否被爬虫执行过,系统都会先直接从搜索服务器获取相关信息,也就是说系统会先从以前存在的数据中找到相似的数据返回给用户,提升用户体验,与此同时如果这个关键词为新的关键词,系统将会通过队列去执行这个关键词相关信息的获取,下一次如果有别的用户或者这个用户过了一段时间回来输入类似的关键词,因为爬虫获取了相关数据,这个用户将看到更加丰富与完整的内容。
关于缓存
大部分相关数据都用Redis进行缓存处理,包括空数据集,为了防止缓存穿透,对空数据集进行了短时间的缓存。同时对所有数据的过期时间也进行了加上随机数的处理,为了不让所有缓存同时过期,瞬时增加服务器负担。
待解决问题
- 查询时间过长(数据库优化与业务逻辑的优化),随着数据的增长,这个为将越来越明显。
- 样式的优化(手机端更好的适配)